Optimized Checkpointing with Tensorstore#
Orbax relies on Tensorstore to store individual arrays in a checkpoint. Tensorstore provides efficient, scalable library for reading and writing arrays.
Until recently, however, our use of Tensorstore came with a few drawbacks. Chief among them was the fact that every parameter in a training state would be saved as a separate directory. This approach can be quite performant, even for models with hundreds of billions of parameters, provided that model layers are stacked. Otherwise, hundreds or thousands of directories may be created in the checkpoint.
This fact can lead to very slow restore times, which is undesirable in and of itself, but is particularly painful for jobs that may be preempted frequently and need to restart, for example.
While it is slightly less of a concern at save time, since writes to disk can happen asynchronously, the synchronous portion of the save can still be slow as many directories are created.
Additionally, if individual parameters are small, storage may be wasted on filesystems with minimum file sizes.
Towards an Improved Checkpoint Format#
The new, optimized checkpoint format provided by Orbax is backed by Tensorstore’s OCDBT driver.
For practical purposes, this means that we will no longer store one parameter per directory, but will aggregate many parameters into a smaller set of large files.
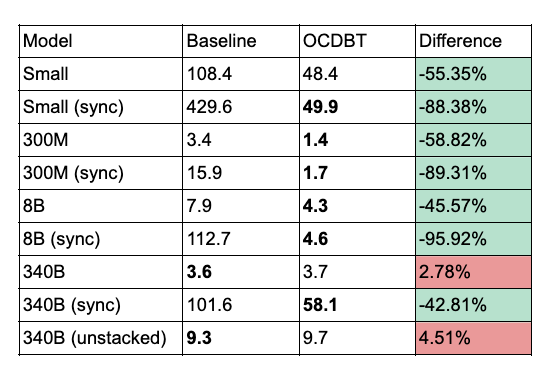
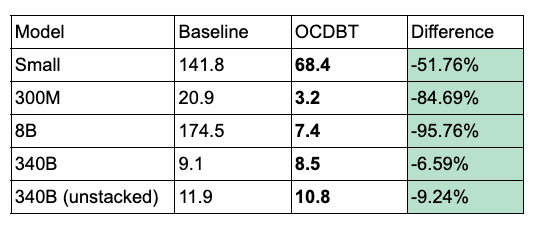
Empirically, we have observed substantial speed-ups in both save and restore when using the new format.
Save Performance (sec)#
Restore Performance (sec)#
Checkpoint Format#
Concretely, what does the new checkpoint format look like in comparison to the old?
Old Format#
f = """
path/to/my/checkpoint/dir/
0/
state/
layer0.param0/
.zarray
0.0
0.1
1.0
1.1
layer1.param0/
.zarray
0.0
...
<another_item>/
...
1/
...
2/
...
Note: in this case, `0.0`, `0.1`, etc. provides an indication of how the array
was sharded when originally saved.
"""
New Format#
f = """
path/to/my/checkpoint/dir/
0/
state/
checkpoint # legacy msgpack file, stores tree structure
tree_metadata # (maybe) new proto file, stores tree structure
d/ # array data stored here
012b2c6e5c9d2a16c240a59d5f0f35c0
056e0816bdc5496a86251e58a0ec202b
...
manifest.0000000000000001
...
manifest.ocdbt
<another_item>/
...
1/
...
2/
...
"""
Enabling the new format#
import jax
import tempfile
import subprocess
import os
from etils import epath
import orbax.checkpoint as ocp
# Initialize PyTreeCheckpointHandler with `use_ocdbt=True`.
# This option already defaults to True, so it's optional to pass it in.
ckptr = ocp.Checkpointer(ocp.PyTreeCheckpointHandler(use_ocdbt=True))
Additional Notes#
All checkpoints previously produced by Orbax in the old format will still be
readable when the new format is enabled. However, if a checkpoint is produced in the new format, it cannot be read if use_ocdbt is disabled.
Custom Chunk Sizes#
Orbax Zarr3, a multidimensional array storage format, offers customizable chunk sizes in bytes for optimal memory management. The default chunk size, which corresponds one-to-one with the array shard size, can cause out-of-memory errors when reading on hosts with different sharding layouts. For example, this can often arise when arrays are saved with a fully-sharded sharding, but loaded with a fully-replicated sharding. To prevent this, set chunk_byte_size smaller than or equal to the anticipated read size. Anything above 1MB generally won’t affect impact performance. Consider following example:
# setup checkpoint data
array_len = 8 * 1024
key = jax.random.PRNGKey(0)
key, subkey = jax.random.split(key)
pytree = {
'a': jax.random.normal(subkey, (array_len, ), dtype=jax.numpy.float32), # 32KB
'b': jax.random.normal(subkey, (array_len * 2, ), dtype=jax.numpy.float32), # 64KB
}
# create save_args to customize the chunk_byte_size
save_args = jax.tree_util.tree_map(
lambda x: ocp.SaveArgs(
chunk_byte_size=
1024, # 1KB
),
pytree,
)
temp_dir = tempfile.TemporaryDirectory()
mgr = ocp.CheckpointManager(epath.Path(temp_dir.name),
item_handlers=ocp.PyTreeCheckpointHandler(use_zarr3=True)) # make sure zarr3 is enabled
mgr.save(
0,
args=ocp.args.PyTreeSave(
pytree,
save_args=save_args,
),
)
mgr.close()
WARNING:absl:Setting the target_byte_size too small could reduce performance.
WARNING:absl:Setting the target_byte_size too small could reduce performance.
Customizing Data File Size#
To improve file I/O parallelism when working with large files on remote storages like GCS, use the PyTreeSaveArgs.ocdbt_target_data_file_size parameter to control the size of output files.
BEFORE#
def print_directory_file_size(dir: epath.Path) -> None:
print(f"dir={dir}:")
for f in data_dir.iterdir():
if f.is_file():
print(f"file={f.name}, size={f.stat().length}")
# continue from above example, examine the data file sizes
data_dir = epath.Path(temp_dir.name) / '0'/ 'default'/ 'ocdbt.process_0'/ 'd'
print_directory_file_size(data_dir)
dir=/tmp/tmpgmlbsi92/0/default/ocdbt.process_0/d:
file=37c935c9225e6ecce2d52617d78255c7, size=99432
AFTER#
temp_dir = tempfile.TemporaryDirectory()
mgr = ocp.CheckpointManager(temp_dir.name,
item_handlers=ocp.PyTreeCheckpointHandler(use_zarr3=True))
mgr.save(
0,
args=ocp.args.PyTreeSave(
pytree,
save_args=save_args,
ocdbt_target_data_file_size=10 * 1024, #10 KB, should be much larger than chunk_byte_size
),
)
mgr.close()
data_dir = epath.Path(temp_dir.name) / '0'/ 'default'/ 'ocdbt.process_0'/ 'd'
print_directory_file_size(data_dir)
WARNING:absl:Setting the target_byte_size too small could reduce performance.
WARNING:absl:Setting the target_byte_size too small could reduce performance.
dir=/tmp/tmp7x6t_uzd/0/default/ocdbt.process_0/d:
file=046df2a1b684a017092de1ed6447d1a7, size=10307
file=74e7d42aede0ca364d151cddfeba2316, size=10350
file=119bdebf60b66242629015acd8674dd7, size=10291
file=db783174039d5510d59075c8c74f0381, size=10316
file=d240d3cd2c78eed73042d0cc24ee2322, size=10282
file=f0674136ded966323b9d31001c72c838, size=10290
file=c87e24be43cca0831500e6f7bc9b68c9, size=10290
file=ed882a60ff0d2cbf8f09f7596782c272, size=17289
file=1703a5c1822f5f9028066fdd6aa137c1, size=10287